---------------------------------------
Text pragmatics and NLP at smartocto
This brings us to the problem that our LABS team - in charge of Research and Development at smartocto - has spent the last few years trying to solve: the analysis of text pragmatics represents the most challenging and, at the time we started, still far from a resolved problem in computational linguistics overall.
We have always worked with the latest language technologies. When I joined smartocto in 2022, I already had extensive experience in developing similar NLP systems and years of work as a Data Scientist at Wikidata, one of the largest and most complex semantic data systems in operation. The team had already been combining various machine learning models with dictionary and rule-based approaches, making significant efforts to enhance traditional mathematical methods by integrating them with human expert knowledge. We continued this work together. I tried to contribute with everything I knew; on multiple occasions we set the problem aside and returned to it, sometimes achieving small, incremental successes, but nothing that truly satisfied us. Even fine-tuning BERT, a famous early transformer-based deep learning model, would not deliver because of the scarcity of properly human-tagged data to train such models with.
Then the Generative AI boom started, making really Large Language Models like ChatGPT and Anthropic Claude available, and we realised that our idea to somehow combine human expert level understanding of the User Needs model with the capacity of LLMs to mimic human language almost perfectly was the key to the solution that we were looking for.
Solution = Knowledge Engineering + LLMs
If you try to present a system like ChatGPT with a specific news article and ask it to identify which User Needs it satisfies, it won't work very well. Trust us – there is hardly an approach that relies solely on that which we haven't already tried. LLMs are generalists that almost perfectly simulate human language and are the first NLP systems sensitive to the pragmatics of text, but they are not omnipotent. Understanding and using the User Needs model requires an experienced journalist or editor, while User Needs analysis requires at least a solid expert in media studies. The way we at smartocto finally solved the problem of how to automatically tag User Needs in any text is based on accepting LLMs for what they are and nothing more: they are simply linguistic machines that allow us to use almost all the information carried by a text under analysis efficiently, something that their machine learning predecessors could not recognise and utilise.
Knowledge Engineering
This is where the methodology of Knowledge Engineering comes into play, in which we apply procedures for the thorough analysis of expert knowledge – such as that encapsulated in the User Needs model – and its codification into a format suitable for processing with AI. We conducted a thorough synthesis of all scattered sources of knowledge about the User Needs model and experiences in its application, and then developed a system for characterising each axis of the model in order to be able to distinguish them. We logged every result in the development of the User Needs 2.0 model (see our User Needs 2.0 Whitepaper) and all insights collected from working closely with news brands across the world. This resulted in a set of rules that we then used to precisely direct LLM-based analyses toward our goal. LLMs are known as few-shot learners - systems capable of quickly learning to respond even to data not included in their enormous training datasets when prompted with particularly suited examples or guidelines. The key to solving the problem of User Needs classification in articles was to first discover the right knowledge representation scheme, and then find the best way to inform the LLM about exactly which text features it needed to observe in order to tag the text accurately.
The User Needs Tagger and Recommender we now have at smartocto are complex, integrated software systems that use LLMs merely as the "engine" of the machine, whose operation depends on the fine details that only human thought could introduce into the process. The standards of our LABS team (comprising mathematicians, cognitive science experts, computer science and machine learning engineers, and analysts) are high.
We were told that all problems would be solved with the advent of generative AI; that any author could analyse User Needs through ChatGPT or a similar system now; that it was only a matter of time before media companies developed specific LLMs to solve not just this but all other related problems in media analytics. None of this has happened yet, and after investing so many years in research, we were not willing to settle for anything less than the real thing.
The combination of expert knowledge via knowledge engineering with LLMs enabled us to perform way beyond the classification problem that we began with. In the latest iteration, our User Needs system takes into account not only the text as such, but also the characteristics of the writing style of any particular media outlet, their objectives, their expectations on various audiences. The smartocto User Need Recommender and Tagger are now integrated with other AI powered services under the common umbrella of the smartocto.ai approach. The integration of User Needs article tags with our well-known dashboards and analytics will follow immediately.
---------------------------------------
Educate me gone wrong?
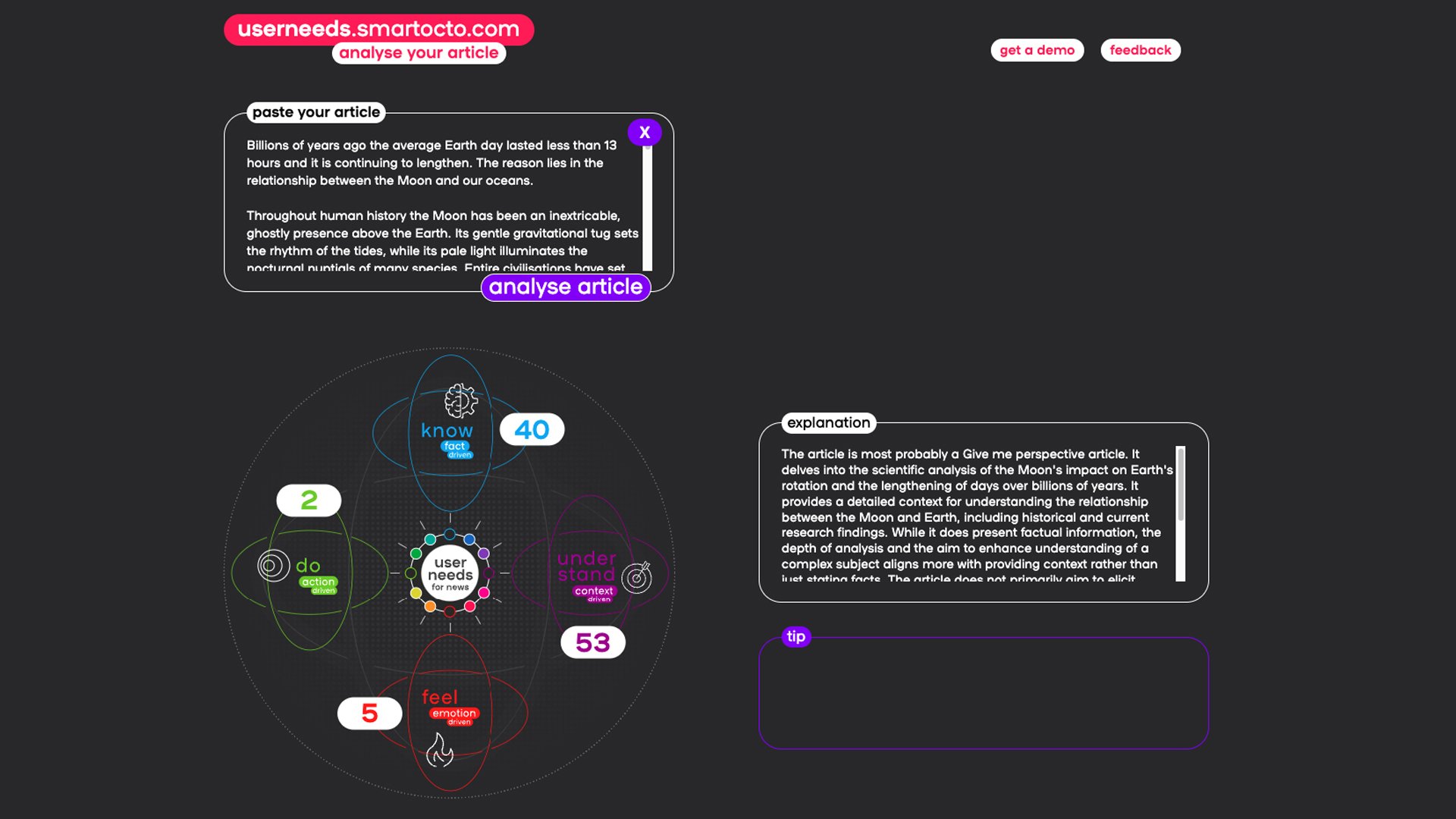
Read this story from the BBC to see how it aligns more with news articles. The introduction seems to suggest that the piece primarily explains why the days on Earth are getting longer.
The article itself is then full of facts and mentions various scientific perspectives. As a result, our Playground becomes somewhat confused, to the extent that you can attribute that human characteristic to AI. The piece is 53% context-driven but also 40% fact-driven. The model finds it difficult to recognise whether the narrative of facts as a whole still contributes to the original purpose of the author. This is the explanation from the tool: