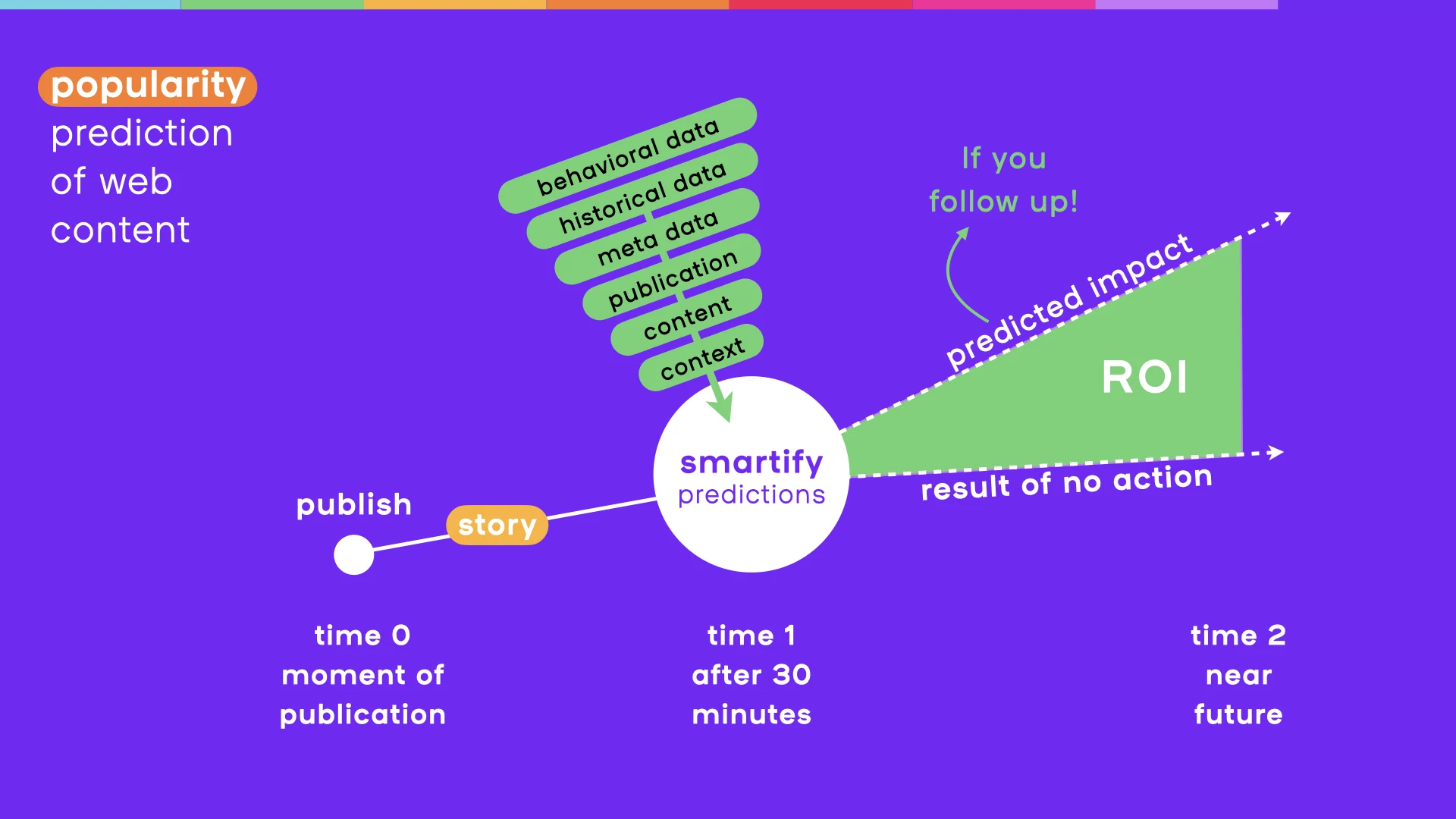
But if we already have a model pre-trained on real, historical data, then for each new post we can ask the model to provide a series of predictions, each prediction made on an assumption that a post would reach some number of impressions. That means that we can analyze any given post and then predict the number of clicks it will reach, conditional on that post reaching 100, 1.000, 10.000, 100.000,.. impressions.
Since impressions necessarily grow with time, in effect we have begun to estimate the time-series of post’s popularity. And since our models are not bad at predicting a post's popularity for a certain number of impressions, we have all the reasons to believe that we can estimate such time-series nicely.
Finally, it turns out to be possible to qualify any given post by a single metric of its future potential in this approach, ranking the posts according to their expected click-through-rate (CTR). And that is how smartify can choose which posts to recommend to its users for further elaboration (e.g. by sharing them, boosting their performance, or following up on the post discussion).