It’s often difficult to recognise the dominant user need associated with any given article. So, we created an AI tool to help. The all-important question is: how good is it?
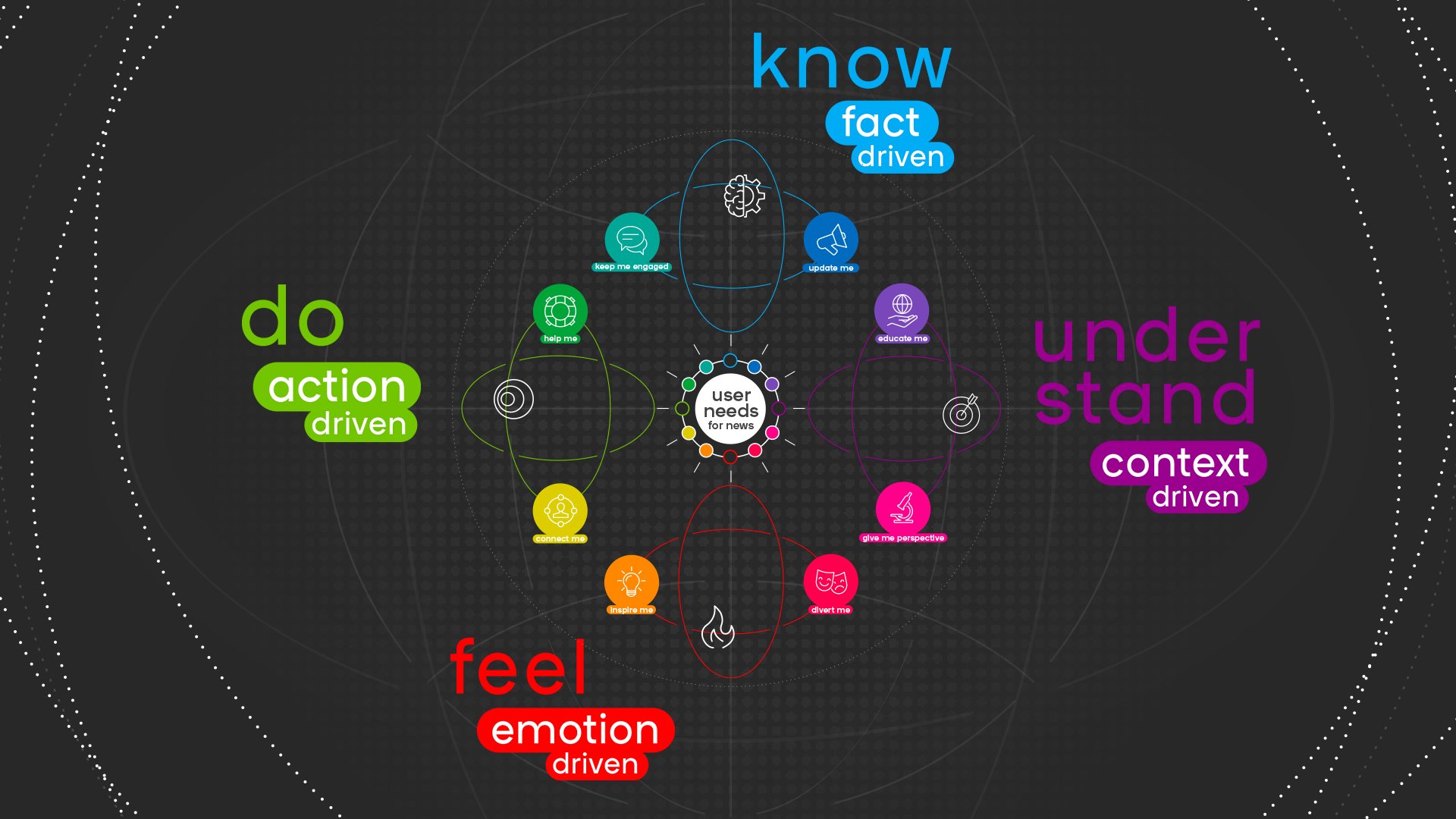
First, a little bit of background. In the User Needs Model 2.0, there are four axes: four different approaches that publishers can orient their content - or output - against. These are know (fact-driven), understand (context-driven), feel (emotion-driven) and do (action-driven).
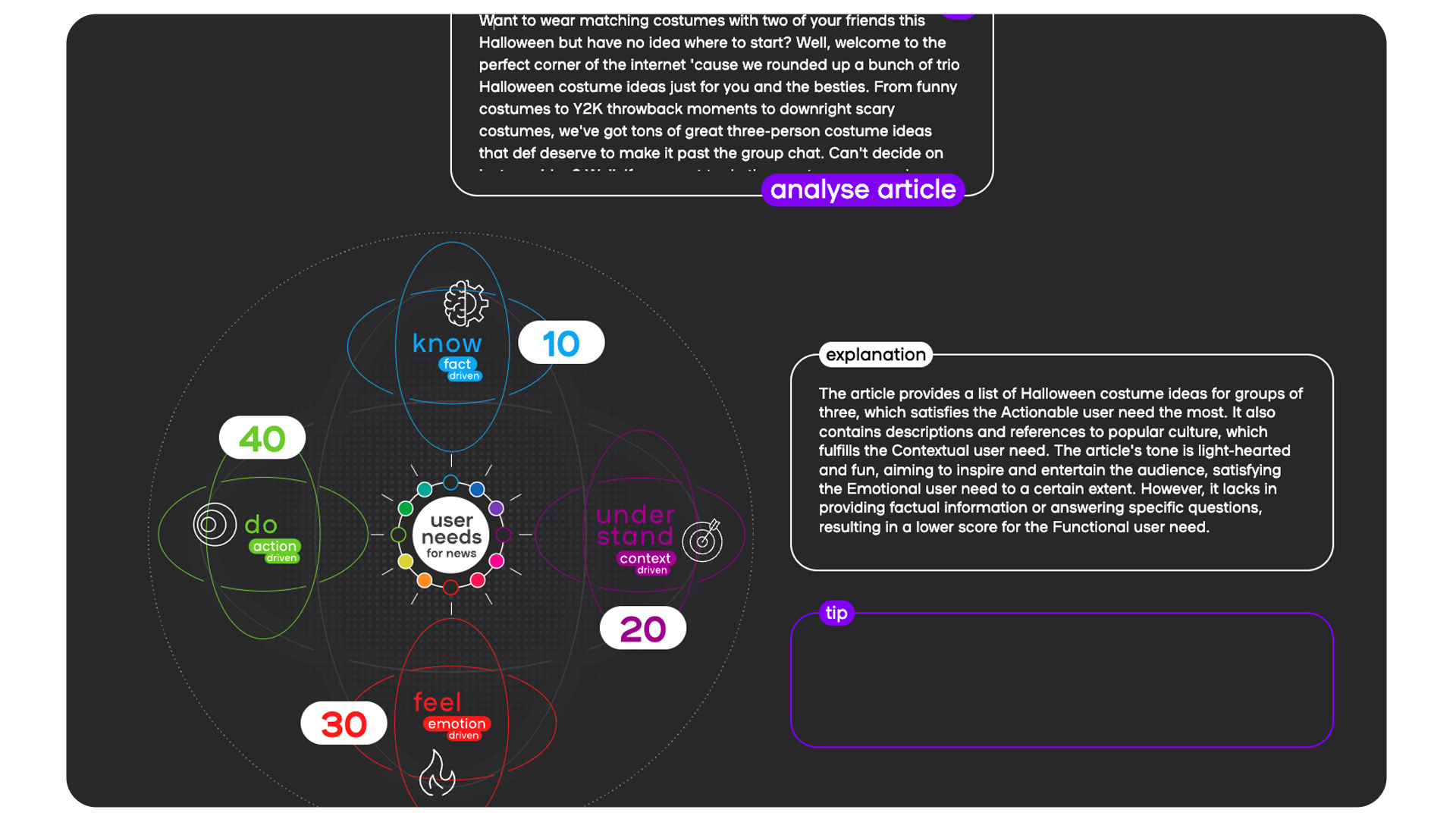
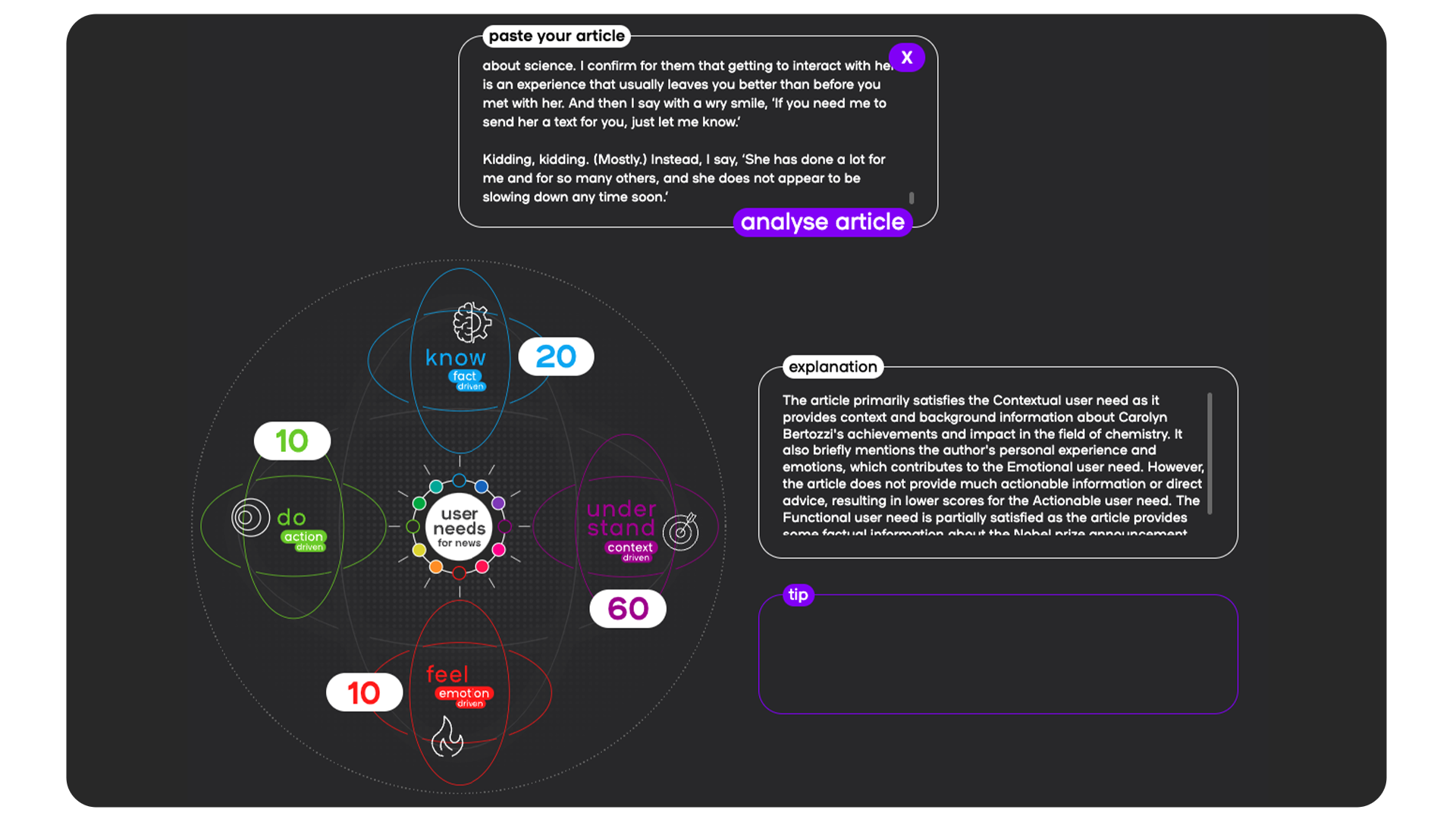
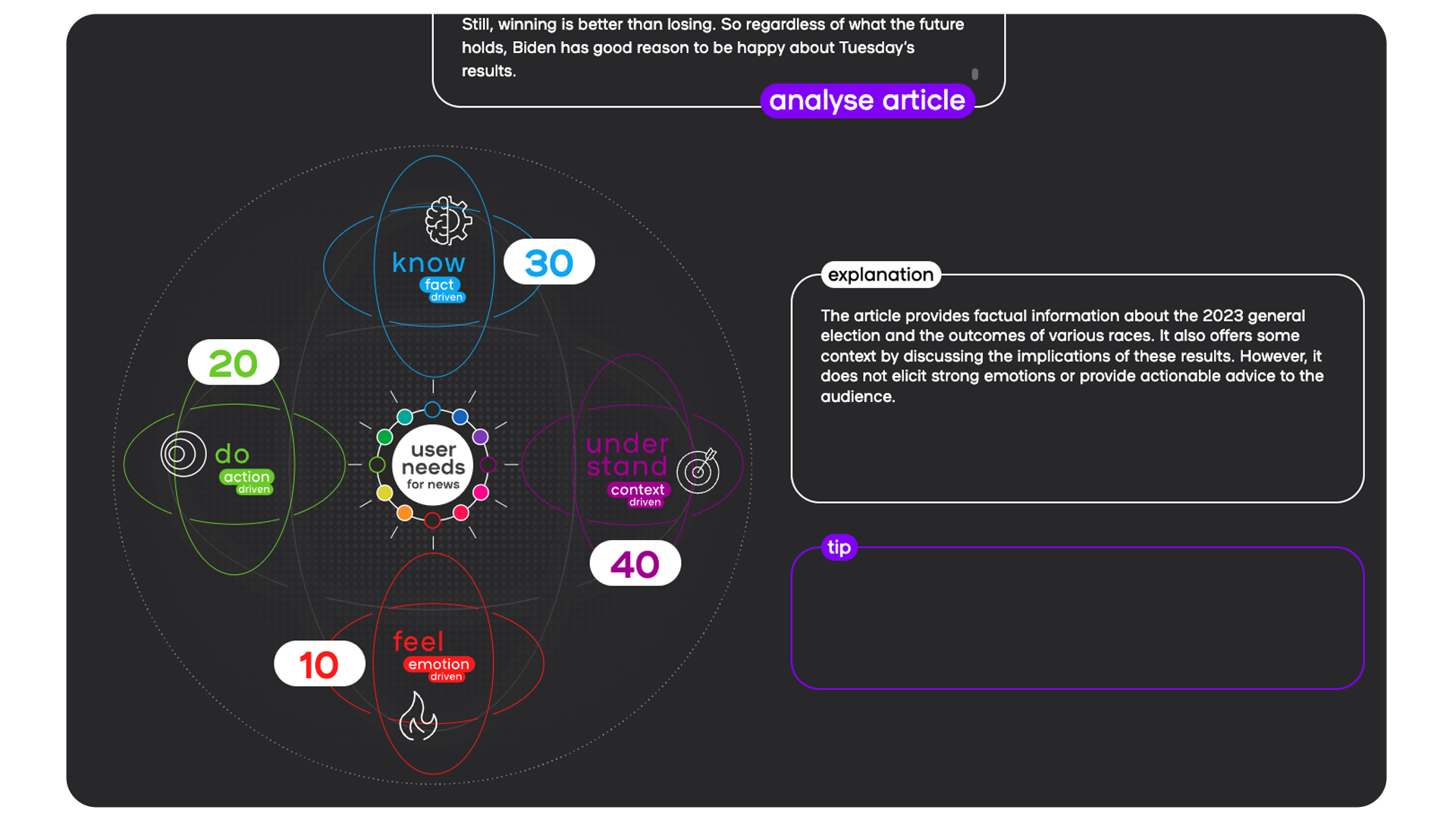
The AI tool userneeds.smartocto.com works by inputting the text of an article, and scoring it against these four drivers, and it enables editors to see instantly where their content sits - and if it’s sitting where it should.
What is prompt engineering?
To do this we use prompt engineering - which means explaining how to score an article on these four axes by sending properly crafted instructions to a Large Language Model (LLM) like OpenAI’s ChatGPT. It’s different from training algorithms or data.
But we’re not done yet. Here’s Goran Milovanovic, our lead data scientist on what happens now:
“We are now developing a system that will rely not only on (a) prompt engineering, but on (b) expert knowledge of the User Needs Model 2.0, expressed in small chunks (sentences, short paragraphs) and encoded in something called a vector database. That expert knowledge is used to enhance prompt engineering in a very well known, standardised framework for the development of AI powered apps and services known as Retrieval Augmented Generation (RAG). In our first project to use this framework, we built a recommender to automatically generate alternative headlines and our smartocto.ai products and services also rely on this framework.”
Two very important takeaways from this explanation:
- We don’t ‘train’ LLMs - or even fine-tune them
- RAGs are used to enhance our prompts
How the AI tool works
Users simply copy the text of any article into the tool.
The model first scores the inputted article on a scale of 0 - 100 on each User Needs 2.0 axis, and then these scores are normalised to add up to 100.
-----------------------------------------------
The axes:
KNOW (the factual news)
CONTEXT (articles with explanation and analysis)
EMOTION (articles that evoke an emotion and strengthen feelings)
ACTION (articles that help and encourage people to act themselves and connect them to a larger movement). Service journalism (‘Help me’ articles) will also be recognised by the system.
-----------------------------------------------